Calculating GPT-2’s inference speedups
I was recently re-reading Finbarr Timber’s post on transformer inference optimizations, and I wanted to try to implement each of these techniques1 in nanoGPT to see how much we could practically speed up inference with GPT-2’s architecture and reduce the computational bottlenecks in the model.
For my benchmark model, I'm going to use the GPT2-XL model weights and load them into nanoGPT. This will let us directly change the modeling code for our optimization tests. All tests will be run on an A100 80GB GPU via Lambda Labs, and below are the sampling parameters for our experiment:
Number of Sequences: 10
Sequence Length: 300
Top K: 200
Temperature: 0.8
Prompt: "Edgar Allan Poe is a”
Precision: torch.float32
Baseline Model:
Overall Generation Stats:
Average time per sequence: 4933.50ms
Average tokens/sec: 62.03
Total time: 49335.02ms
Average GPU Memory (MiB): 7092.7500MiB
Sampling Output:
sample 0: Edgar Allan Poe is a familiar name to many who receive their news from a television. When I was growing up, I watched The Twilight Zone on the A&E channel and for years, whenever I heard a news broadcast, the announcer would introduce him as "a famous writer of horror stories," or "a famous writer of supernatural tales." In other words, his name was synonymous with a particular genre: horror.
There are two reasons I was surprised to learn that Edgar Allan Poe was actually a novelist. First, Poe's work is quite unlike that of a horror writer. One of the things that set him apart was that he was averse to ghosts, goblins, and monsters. Unlike Poe, many authors of horror fiction often depict ghosts and monsters with a sense of inevitability — the ghost is here, the ghost will stay. Poe's stories are more surprising, more disquieting, and more terrifying. I imagine that Poe's readers felt nothing but dread when they read the stories in which he was the main character….
Our naive model is only generating 62 tokens per second 🙁. In order to speed up inference, we generally want to focus on the most compute-intensive parts of the model, and one optimization is to create a KV cache that stores our key and values projections in memory, which saves time on the recalculation of past tokens in the forward pass of the attention layer.
KV Cache
In very simple terms, within the attention block the query is the token we are currently looking at, the key is the previous context we want to attend to, and the value is the weighted sum of this context2. Our attention blocks are wasting compute by recalculating the q, k, and v projections every time we pass in a token. When generating the current token, the model needs to pass in N previous tokens as context for the attention formula. This previous context is needed for attention, but the other parts of the model (MLP, embedding layers, classification head) don’t need the previous context, as they process tokens in parallel.
Right now, we are redundantly calculating the key and value projections for all previous tokens at each timestep, even though this previous context hasn’t changed from before. KV Cache frees up computation by storing the key and value projections for the past tokens that we’ve already calculated. This adds state into our model, but we now only have to compute the attention formula for just the current token, and we pull the previous key from memory to get the context for the attention calculation.
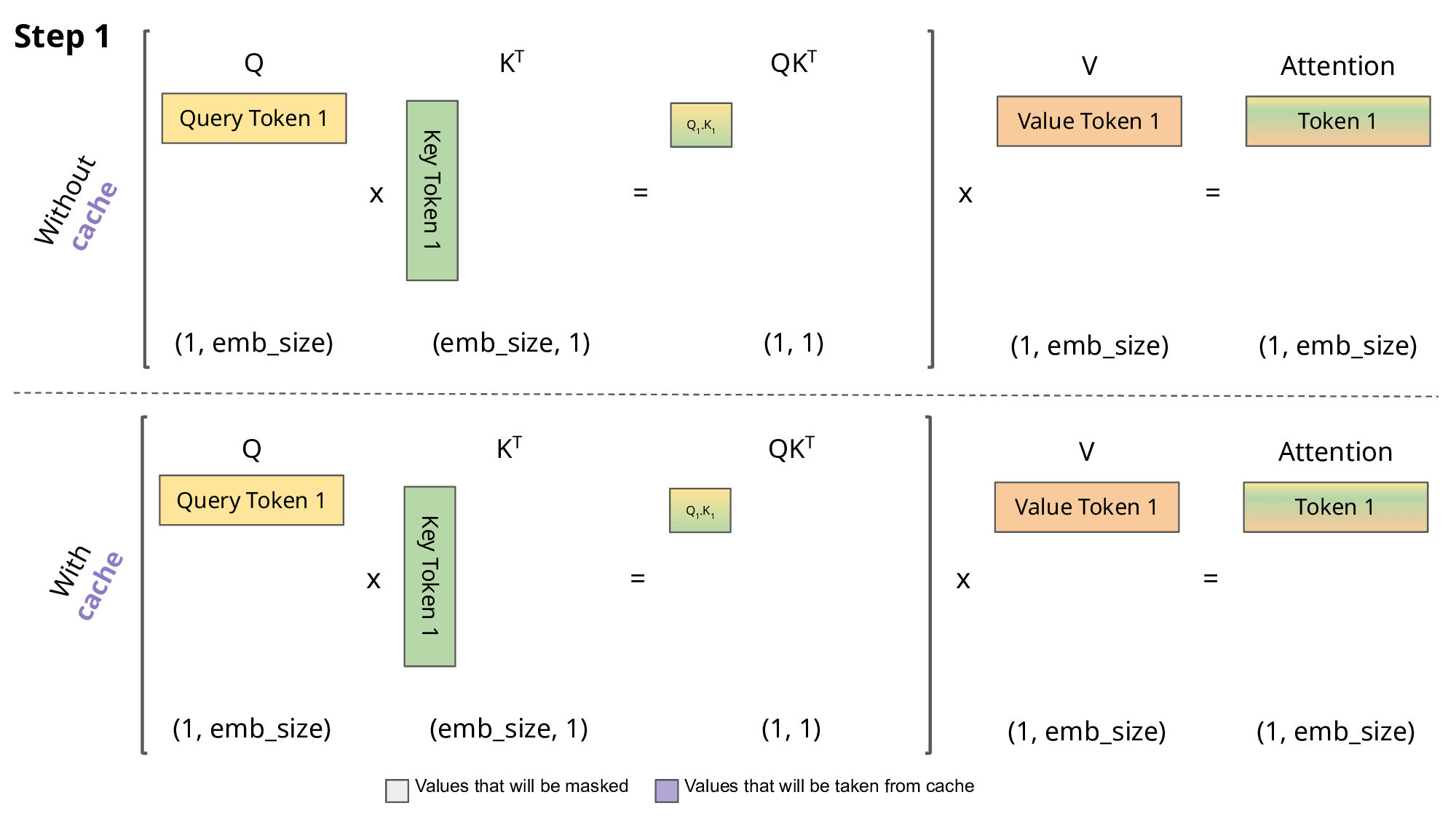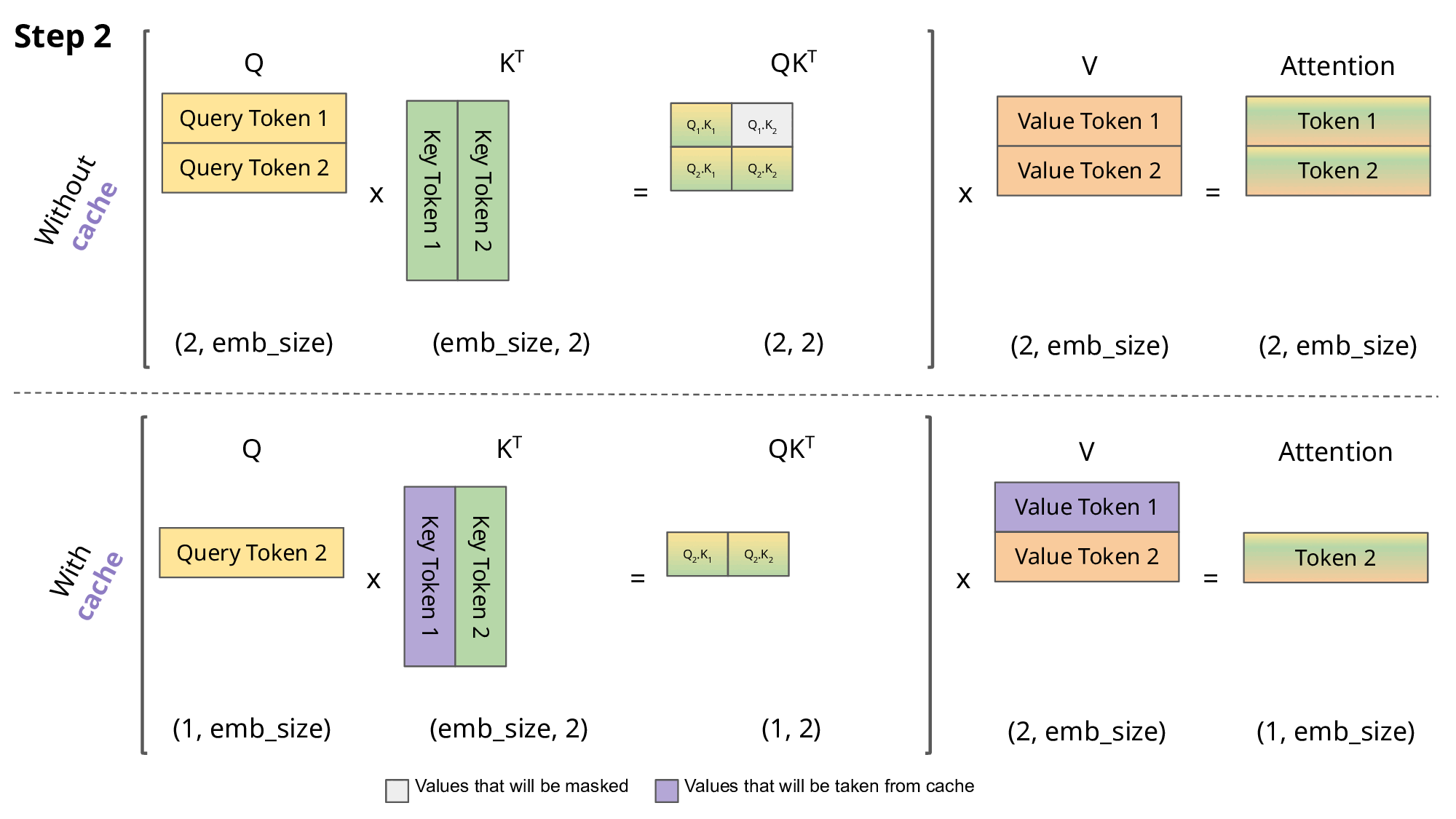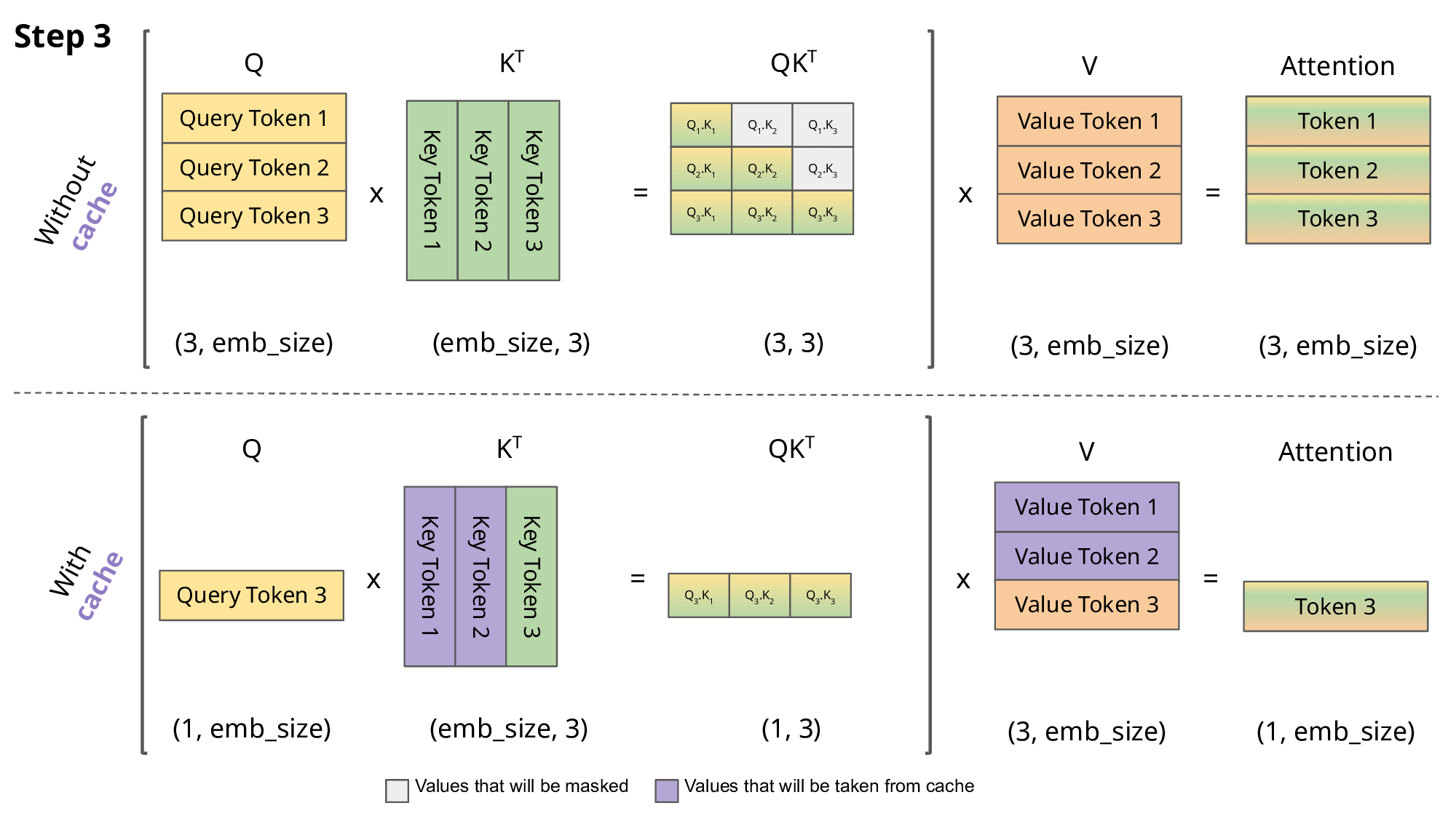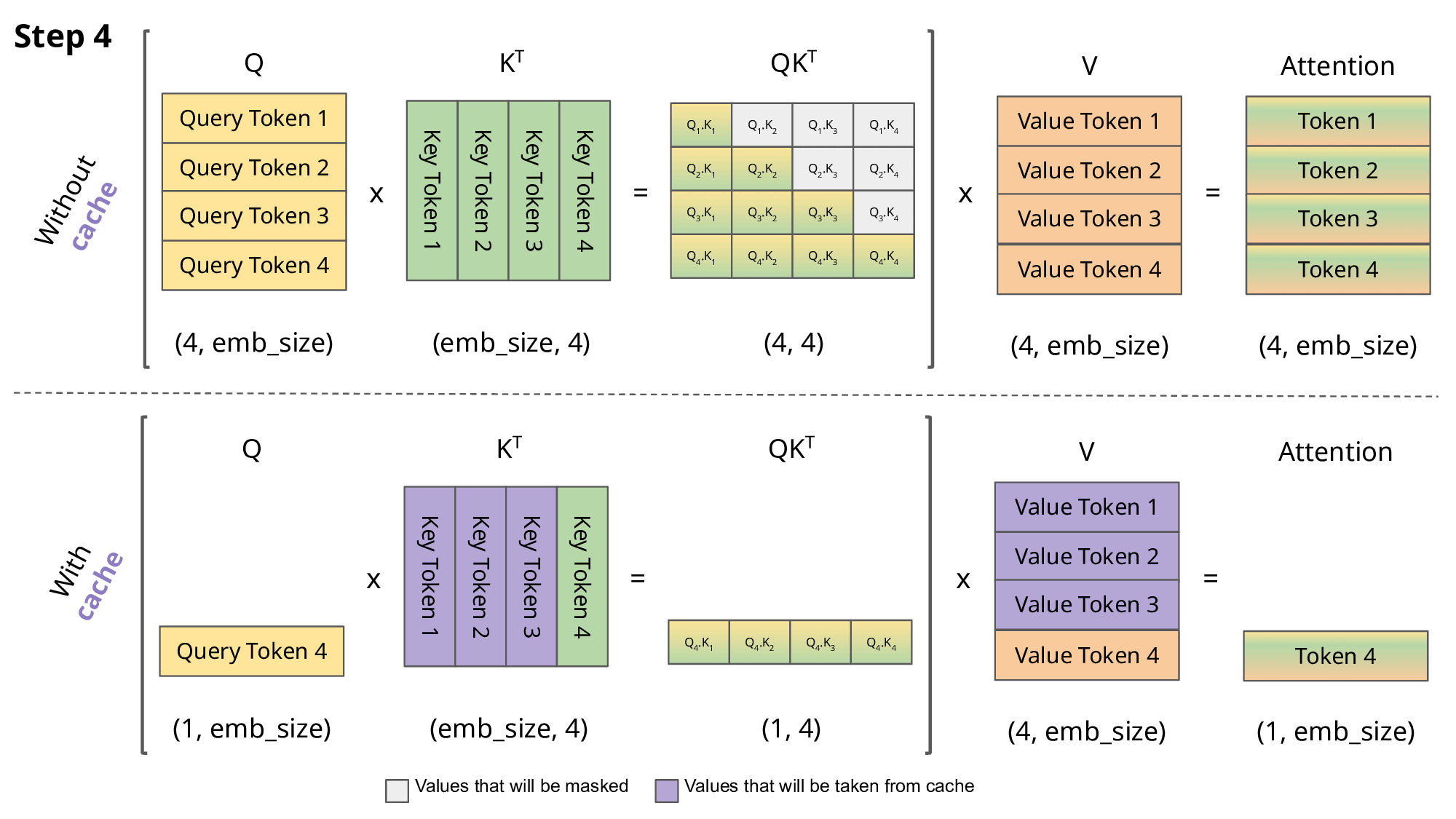
KV Cache (source)
Implementing the KV Cache is relatively straightforward. For each attention block in our transformer, we want to register two torch.Buffer objects that will store the key and value projections. These buffers will be initialized at the maximum length of the generation sequence, and during attention we will look at cached key-value pairs up to the current input token, and ignore the unused portion of the buffers.
class CausalSelfAttention(nn.Module):
def __init__(self, config):
super().__init__()
...
# Register key and value cache buffer - stores key and value projections for attention
self.register_buffer('k_cache', torch.zeros([batch, n_head, seq_len, head_size], dtype=dtype))
self.register_buffer('v_cache', torch.zeros([batch, n_head, seq_len, head_size], dtype=dtype))
In the forward() function, there are two cases: the first case is to initially process the full prompt sequence with standard causal masking, and in the second case, we switch to only focusing on the current token and update our k_cache and v_cache with the current token, using the stored values for the next generation step. We also skip the causal mask now that we are just processing one token. This simplifies the attention computation from quadratic to linear complexity , since we don’t need to recompute attention scores from the past.
def forward(self, x, input_pos=None):
B, T, C = x.size() # batch_size, seq_length, n_embd
q_proj, k_proj, v_proj = self.c_attn(x).split(self.n_embd, dim=-1)
...
# Update current position with k_proj and v_proj in cache if one token, otherwise it's full sequence
if input_pos is not None:
self.k_cache[:, :, input_pos, :] = k_proj
self.v_cache[:, :, input_pos, :] = v_proj
# Use cache + current token for new k and v
k = self.k_cache[:, :, :input_pos+1, :]
v = self.v_cache[:, :, :input_pos+1, :]
else:
k = k_proj
v = v_proj
# Attention formula
att = (q_proj @ k.transpose(-2, -1)) * (1.0 / math.sqrt(k.size(-1)))
# Only mask when processing full sequence, otherwise skip causal mask
if input_pos is None:
att = att.masked_fill(self.bias[:,:,:T,:T] == 0, float('-inf'))
...
Finally, I took this tip from GPT-Fast, but we are implementing a static KV cache of a fixed sequence length at each attention block. Since these buffer sizes are constant, we can run torch.compile to optimize the memory layouts efficiently and take advantage of JIT optimizations, which allows the entire generation sequence to be compiled into a single optimized graph. This is more efficient than a dynamic cache approach, where the buffer size would grow and prevent torch.compile from effectively recognizing the access patterns into fused kernels.
To test the KV Cache speedup effectively, we will be generating sequences of 300 tokens in order to make sure that we are in the compute bound region3.
Baseline + kvcache + torch.compile
Overall Generation Stats:
Average time per sequence: 1732.01ms
Average tokens/sec: 176.67
Total time: 17320.06ms
Average GPU Memory (MiB): 7845.2500MiB
Through KV Cache and optimizing our memory layout with torch.compile, we reduce the computational overhead by 2.8x!
Speculative Decoding
I wrote about speculative decoding before, but this is a great optimization if you have extra compute available. Speculative decoding pairs a larger target model with a smaller draft model that share similar architectures and are typically trained together. The draft model predicts K tokens ahead, and the target model verifies which draft tokens to keep. This works well because the draft model handles the generation of common phrases and predictable tokens, while the target model handles more complex, context-dependent predictions. By combining the two models, speculative decoding should accelerate the inference speed.
There are three key steps to speculative decoding. First, the draft model decodes K tokens ahead, and we run the draft logits through the target model to get the target logits. Then we convert both outputs to probability distributions that we compare.
def speculative_decode(target_model,draft_model, cur_token, input_pos, speculate_k=4)
# Step 1: Generate draft logits and target logits
# Generate K draft tokens
draft_tokens, draft_logits = generate_k_tokens(draft_model, cur_token, input_pos, speculate_k)
# Run draft tokens through target model to get target logits
target_logits = forward(target_model, cur_token + draft_tokens, input_pos + speculate_k + 1)
# Convert raw logits to probability distributions
target_probs = softmax_probs(target_logits)
draft_probs = softmax_probs(draft_logits)
...
Next, we verify the tokens through comparing probabilities. If the target probabilities exceed the draft probabilities for the token, we accept it automatically - this means the target model agrees with the draft model's prediction. If the draft probability is higher than the target probability, it means the target model is considering other tokens instead of the draft's choice. In this case, we accept the token with a probability of .
def speculative_decode(target_model, draft_model, cur_token, input_pos, speculate_k=4)
...
# Step 2: Compare token probabilities
draft_probs = draft_probs[0 ... speculate_k]
target_probs = target_probs[0 ... speculate_k]
# Calculate acceptance probability and find where rejections occur
accept_prob = min(1.0, (target_probs / draft_probs))
rejected_location = torch.rand_like(accept_prob) > accept_prob
...
If we reject a token, then we need to resample. We take the difference between the target and draft probabilities, and keep only the positive differences via ReLU. We then normalize the differences and get the probability distribution, and then sample the next token from this distribution.
However, if all K draft tokens are accepted, we have a mini-optimization that we can take advantage of! We can directly sample the last position of the target probabilities, and this is computationally free since we already computed this probability when we initially forwarded the target model. We can then sample this last position and move to the next token.
def speculative_decode(target_model,draft_model, cur_token, input_pos, speculate_k=4)
...
# Step 3: Rejection Sampling
if rejected_location is None:
# Scenario 1: All draft tokens have been accepted
# sample the last kth token from target probs, we already did it "for free"
last_token = sample(target_probs[-1])
# update position in the draft model
forward(draft_model, draft_tokens[-1], input_pos + speculate_k)
return torch.cat([draft_tokens, last_token])
else:
# Scenario 2: Resample + normalize from the diff of target_p and draft_p
draft_probs = draft_probs[0 ... rejected_location]
target_probs = target_probs[0 ... rejected_location]
# (q - p)+ from the algorithm
reject_probs = F.relu(target_probs - draft_probs)
reject_probs = reject_probs / reject_probs.sum()
# resample
next_token = sample(reject_probs)
return torch.cat([draft_probs, next_token])
Now this might be a dumb experiment since our model is only 1.5B parameters 😅. Typically we see speculative decoding utilized with a target model like Llama 70B and a draft model like Llama 7B. However, this should still work with the GPT-2 family of models (124M - 1.5B) because they share the same architecture and training data.
Below are the results using GPT2-medium (350M) as the draft model (K=4) and GPT2-XL (1.5B) as the target:
Baseline + speculative decoding:
Overall Generation Stats:
Average time per sequence: 3373.82ms
Average tokens/sec: 88.92
Total time: 33738.20ms
Average GPU Memory (MiB): 8579.7500MiB
Theoretically we should’ve gotten a 2-3x speedup, but we get about 1.46x. I think this makes sense since our target model is already small and not much larger than our draft model. With larger model pairs like 70B/7B, we would see a larger speedup due to the difference between the two model sizes.
Also, speculative decoding can hurt your performance and output quality if the two models aren’t aligned well. Both models should be trained together and have similar architectures, otherwise you might encounter higher token rejection rates. The goal is to find the smallest draft model that maintains a high enough token acceptance rates with the target model.
Quantization
OpenAI's GPT-2 originally used float32 (32-bit floating point) precision for its model weights, which causes some unnecessary bottlenecks because float32 consumes 4 bytes per parameter. Loading float32 weights means that the transfers from memory to compute units is slow, and as a result we waste time waiting for the weights to be fetched during inference. Quantization helps by using lower precision data types like float16 or int8 instead of float32. This reduces both computation and memory costs during inference, and gives us access to larger compute profiles that can handle more operations as shown in A100’s specs table below. While quantization would benefit training more than autoregressive sampling, it still improves inference speed with minimal quality impact through faster memory access.
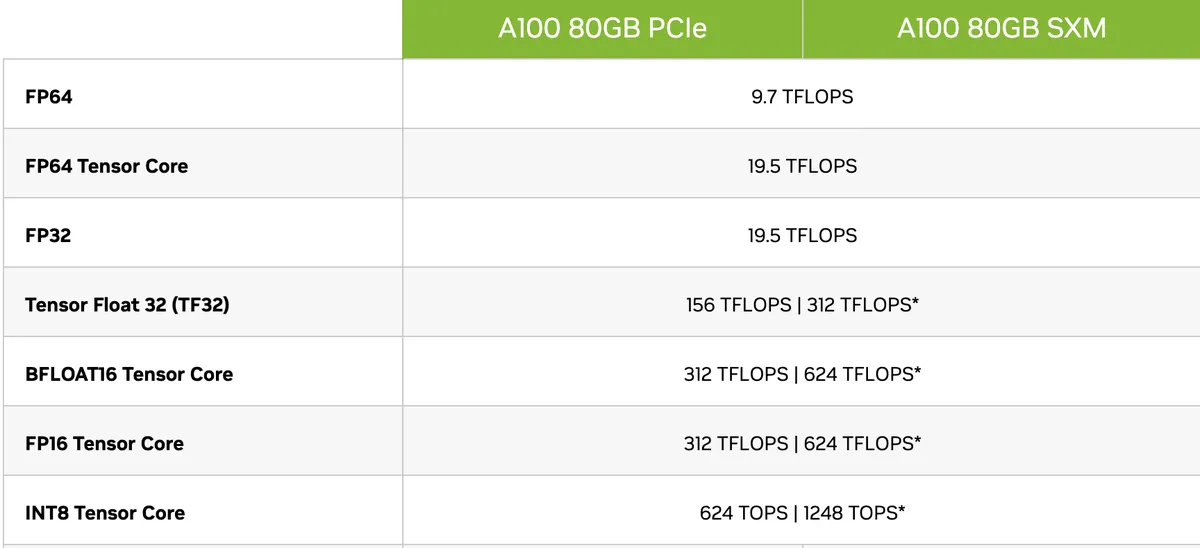
A100 specs (source)
Converting float32 to float16 is simple because both precisions use the same representation scheme. Both formats have three components: a sign bit that tells us if a number is positive or negative, exponent bits that define the range of our number, and mantissa bits that represent the precision we use for a number. Moreover, converting between float32 and bfloat16 keeps the same number of exponent bits, so this conversion is mainly about reducing precision.
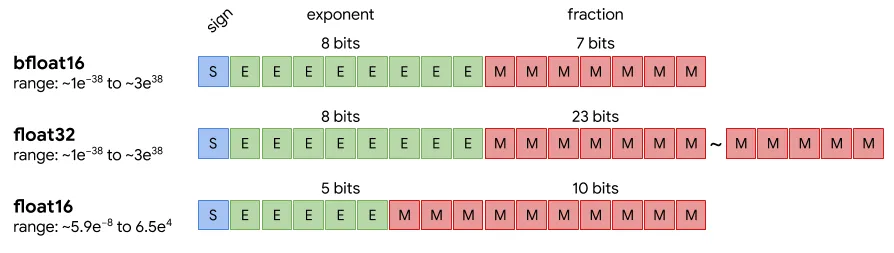
Floating point formats (source)
Baseline + kvcache + torch.compile + torch.bfloat16
Overall Generation Stats:
Average time per sequence: 942.84ms
Average tokens/sec: 324.55
Total time: 9428.39ms
Average GPU Memory (MiB): 3701.7500MiB
Simply reducing precision to torch.bfloat16 with our current model speeds up computation and reduces our memory footprint by 1.8x. Most large language models now typically run in float16 since it maintains model quality while providing significant performance benefits through faster compute and lower memory usage.
Going from float32 to int8 is a bit more complicated since we are switching from float-based representation to integer-based representation. Int8 has only 256 distinct values, while float32 has around 4.2 billion distinct values. To handle this, we need to be able to map our float32 values into int8's smaller range. The first metric we calculate is the scale factor that shrinks our parameters down to int8, and the second value is the zero point that maps the location of zero in float32 into int8’s range. Symmetric Quantization sets this zero point to 0, while asymmetric bases it on the minimum and maximum values in the float32 range.
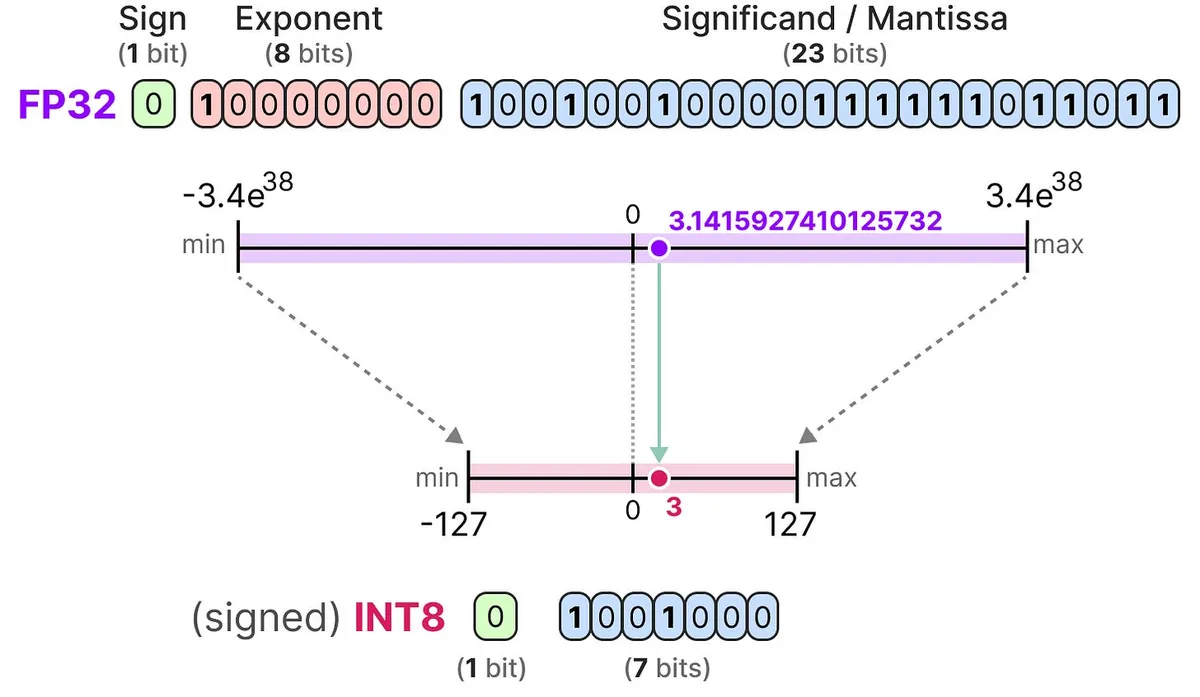
float32 vs int8 (source)
Luckily, TorchAO makes int8 quantization very simple. It automatically finds the best scales and zero points for each tensor during inference to minimize the errors between float32 and int8. In this case, we will focus on int8 weight-only quantization. The weights are quantized to int8, while the activations are kept in bfloat16, and the weights are dequantized back down to bfloat16 before computation. Moreover, we want to get the performance benefits of int8 so we need to torch.compile to fuse the kernels.
from torchao.quantization.quant_api import (
quantize_,
int8_weight_only
)
quantize_(model, int8_weight_only(), device="cuda")
Baseline + kvcache + torch.compile + int8_weight_only
Overall Generation Stats:
Average time per sequence: 806.33ms
Average tokens/sec: 379.50
Total time: 8063.30ms
Average GPU Memory (MiB): 3227.8875MiB
We only see a 1.1x speedup switching to int8 weights. It would've been better to benchmark larger context sizes in order to see bigger gains in speedup. We also saw a bit of degradation in the sampling quality going to int8, which makes sense given how small our model is.
Update 12/04: Looking back at my test code, I realized I mismatched the configuration and the new KV cache architecture in the GPT-2 model, I was doing it based off the old GPT2 architecture. After fixing the quantization settings and switching it over to the KV cache implementation, we get the expected 1.5x speedup, which is more consistent with typical int8 weight-only quantization performance improvements.
Overall Generation Stats:
Average time per sequence: 537.55ms
Average tokens/sec: 569.25
Total time: 5375.53ms
Average GPU Memory (MiB): 3202.25924MiB
Flash Decoding
For training language models efficiently, FlashAttention significantly speeds up training by optimizing how self-attention handles memory bandwidth in an IO-aware manner. Specifically, it targets the bottleneck of reading and writing intermediate results in the attention calculations. Flash attention parallelizes across the batch size and the query length dimensions during training, but during inference we run with batch_size=1 and query_length=1 when using our static KV cache. This means that flash attention's optimizations don’t apply directly to inference, and we underutilize the GPU’s compute since we only process a single new token while the rest of the values remain pre-computed and stored in the KV Cache. This is unfortunate, as both KV Cache and flash attention are great strategies that optimize memory access patterns, and we want to combine the two approaches effectively.
Flash Decoding solves this by adding the keys/values sequences as another parallelization dimension in flash attention. First, it splits the key/value pairs into chunks and computes the attention between each chunk and query in parallel. Then, it performs a reduction step to combine these parallel computations into the final output, ensuring each chunk's contribution is properly weighted. This approach increases GPU utilization during inference while maintaining the memory efficiency benefits of both flash attention and KV Cache.
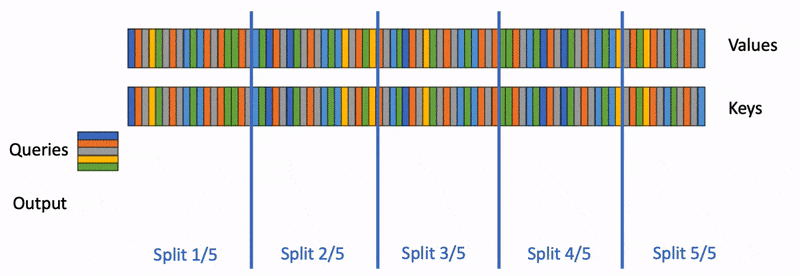
Flash Decoding (source)
In order to implement this in our code, we need to integrate the static KV Cache and torch.compile with the flash attention package. The main issue is making torch.compile work with third-party operations, which can be done using torch.library. Torch.library is an API collection in PyTorch designed for extending its core operator library, and it lets us create and register new custom operators that can integrate smoothly with PyTorch's native C++ library. This lets us maintain compatibility with torch.compile.
The registration process via torch.library involves several steps. First, we define a custom CUDA operator that takes in tensors/shapes as inputs from flash decoding. Second, we implement this operation for CUDA devices by calling flash_attn_with_kv_cache via the flash attention package. We then register an abstract implementation for tracing, which helps torch.compile understand the tensor shapes without actually executing the operation. Finally, we create a wrapper function to call the flash decoding operation and apply torch.compile to achieve speedups.
import torch
from flash_attn import flash_attn_with_kvcache
# 1. define the custom operator for flash attention + KV cache
torch.library.define(
"mylib::flash_attn_kvcache_wrapper",
"(Tensor q, Tensor(a!) k_cache, Tensor(a!) v_cache, Tensor k, Tensor v, Tensor cache_seqlens) -> Tensor",
)
# 2. Implement the CUDA version of our custom op
@torch.library.impl("mylib::flash_attn_kvcache_wrapper", "cuda")
def flash_attn_kvcache_wrapper(q, k_cache, v_cache, k, v, cache_seqlens):
return flash_attn_with_kvcache(
q, k_cache, v_cache, k=k, v=v, cache_seqlens=cache_seqlens
)
# 3. Register a fake implementation for tracing
@torch.library.register_fake("mylib::flash_attn_kvcache_wrapper")
def flash_attn_kvcache_wrapper_abstract(q, k_cache, v_cache, k, v, cache_seqlens):
# Return an empty tensor with the same shape as the query for shape inference
return torch.empty_like(q)
# 4. Wrapper, apply torch.compile to this function
def flash_attn_wrapper(q, k_cache, v_cache, k, v, cache_seqlens):
y = torch.ops.mylib.flash_attn_kvcache_wrapper(
q, k_cache, v_cache, k, v, cache_seqlens
)
return y
...
# Reshape GPT-2 tensors to FlashAttention format [B, nh, T, hs] -> [B, T, nh, hs]
q = q.transpose(1, 2)
k = k.transpose(1, 2)
v = v.transpose(1, 2)
k_cache = self.kv_cache.k_cache.transpose(1, 2)
v_cache = self.kv_cache.v_cache.transpose(1, 2)
# Run flash decoding, convert back to GPT-2 format
y = flash_attn_wrapper(q, k_cache, v_cache, k, v, cache_seqlens)
y = y.transpose(1, 2)
Baseline + kvcache + torch.compile + bfloat164 + flash decoding
Overall Generation Stats:
Average time per sequence: 828.83ms
Average tokens/sec: 369.08
Total time: 8287.95ms
Average GPU Memory (MiB): 4106.6875MiB
Flash Decoding achieves a 1.1x increase in tokens per second. We are testing a smaller model and a shorter context length of 300, which as a result doesn’t fully utilize our GPU compute. For comparison, CodeLlama-34B saw larger speedups when processing context lengths over 10,000 tokens. More importantly, keeping the weights in bfloat16 resulted in minimal sampling degradation, and lets us achieve int8 speeds while maintaining bfloat16 precision.
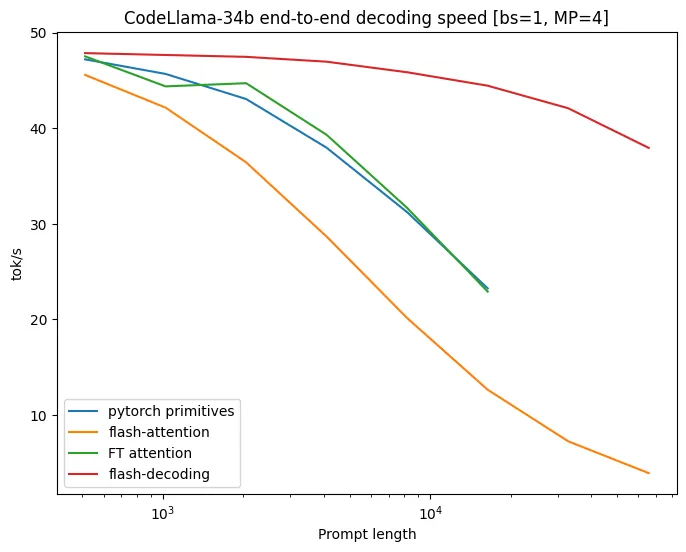
CodeLlama-34B benchmarks (source)
Conclusion
Overall, this was a good exercise to see how some modern inference speedups could apply to the GPT-2 model. In the future, I should’ve better assessed sampling quality by measuring the perplexity, and see how much quality degradation occurred. I would also like to test a larger model, as I think I would see more substantial gains, especially for the speculative decoding section. Finally, testing with just 300 tokens doesn’t fully show the quantization and flash decoding speedups, and running the same experiments with much longer contexts would've probably shown larger performance gaps, as we would’ve utilized more GPU capacity over the extended sequences.
Special thanks to the authors of GPT-Fast and Finbarr Timbers for the initial inspiration of this article.
I’m going to skip effective sparsity because I’m not sure there is too much support in the PyTorch library for an effective implementation (I could be very wrong on this) but this would be a good blogpost in the future for implementing an inference engine or kernels around activation sparsity.↩
I would recommend reading Jay Allamar’s Illustrated Transformer article if you want to brush up on your transformers and attention understanding, he does a great job of explaining the purpose of query, key, and value projections.↩
For the KV Cache to be effective, the model must be compute-bound (limited by FLOPs) rather than memory-bound (limited by memory access). On an A100 80GB we get 312 teraflops per second of float16 compute and 1.5 TB/s of memory bandwidth, and this ratio comes out to roughly 208 tokens. Below this threshold, the bottleneck is memory, and the implementation won’t be as effective because of cache storage and memory overhead. At 300 tokens, we are well into the compute-bound region where the KV Cache can effectively reduce redundant calculations. This is a great article that goes over the arithmetic around transformers inference and KV Cache.↩
Flash Attention requires either FP16 or BF16 precision and does not work with FP32. It was designed to optimize memory usage specifically for 16-bit formats.↩