Finetuning CLIP to predict art styles in Midjourney
This past week, I came across the DiffusionDB dataset curated by the Polo Club of Data Science at Georgia Tech. They scraped over 14 million image-prompt pairs collected from users generating images in the Stable Diffusion Discord. Each entry includes the image and the text prompt used to create the image, along with detailed metadata such as the sampler settings, image properties, and usernames.

Source: DiffusionDB
In their research paper, they analyzed how the images and prompts were visualized in the CLIP embedding space. They projected the embeddings from the text encoder and visual encoder into separate UMAP visualizations. Within the prompt embedding space, they found that there were distinct semantic areas where artistic images and photographic images were located.
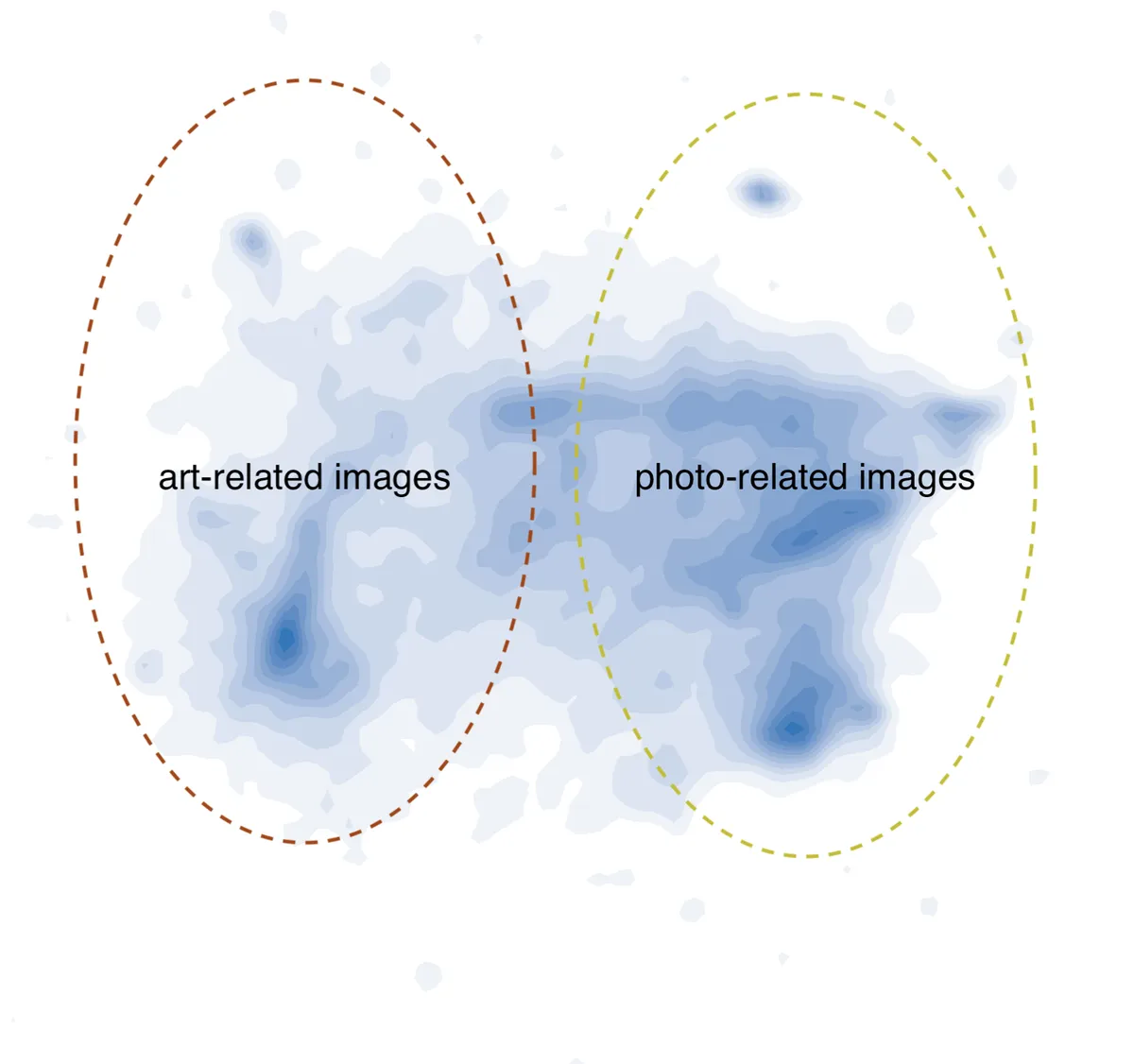
Source: DiffusionDB Explorer
For the image embeddings, the authors don’t reveal much about which art styles appear in specific regions, but they do state that the semantic representations between prompts and generated images don't align perfectly between spaces.
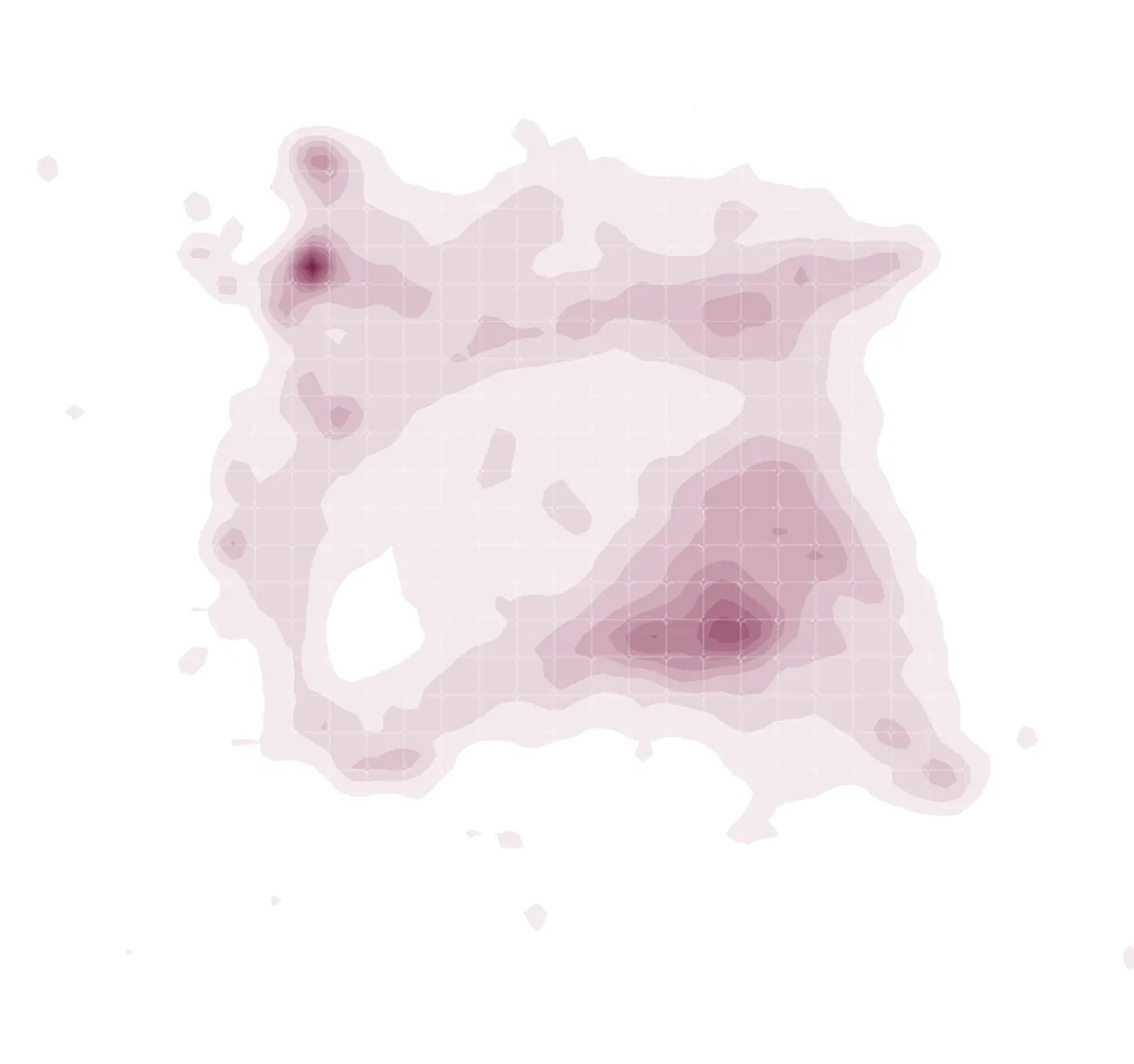
Source: DiffusionDB Explorer
I'm interested in getting a more granular understanding of the different artistic styles (anime, photorealistic, oil painting, watercolor, etc.) that users were generating in the Stable Diffusion discord, and seeing how these styles were distributed in the CLIP embedding space via a UMAP visualization.
I recently read Snat's blogpost on how he classified PDFs across the internet. Basically, he used an LLM to generate classification labels for a 500k sample in his dataset, and then he finetuned traditional and embedding models to classify his entire corpus. This method was based on the Fineweb paper, where the HuggingFace team created a filtered educational dataset by using an LLM to rate educational quality of a 500k sample, and then trained an embedding model on this labeled dataset. Model-filtering approaches are very effective - the Llama team has used similar techniques in the past to build text-quality classifiers for improving their training data.
Following this approach, to get a more detailed visualization of the type of art styles in this dataset, my goal was to take a 500k subset of DiffusionDB, use an LLM to classify the different art styles based off the prompts, train a classifier by finetuning an embedding model, and then visualize the CLIP embeddings along with the category predictions.
We could then apply this classifier to other image generation platforms like PlaygroundAI and Midjourney, and gain insights into the art style distributions across different platforms.
Prompt Quality
Initially, I planned to just take the metadata portion of the dataset and finetune solely on the prompt categories for each image. However, when I examined the prompts I found that there was a big discrepancy in the data quality. Unfortunately because this dataset is sourced from Discord, there were several quality control issues that I found:
- Foreign languages: non-English prompts could complicate the classification process and reduce accuracy.
- Prompt length: Prompts with less than 15 words provided insufficient context for any meaningful style classification.
- Incoherent text: Some prompts were nonsensical, for instance a string of emojis "😂😂😂😂😂" as a prompt makes classification impossible.
- Generation parameters: Different sampler settings, specifically the CFG (classifier-free guidance), significantly influence how effective the prompt controls the generated image.
Additionally, if we wanted to use this classifier for other image generation websites, other platforms have their own unique controls and vernacular that won’t translate directly to the DiffusionDB dataset. Midjourney users for instance use parameter suffixes that they append to their prompt like —ar 16:9 to control the aspect ratio and other image settings.
Given the challenges with prompt quality and platform-specific syntax, I don’t think it would be a good idea to train our model on prompt data, as it would likely introduce significant noise and reduce the classification accuracy. Moreover, if we trained a classifier solely on the prompts in DiffusionDB, we would probably struggle to generalize across different image platforms. As a result, I think just focusing on the image data and extracting the visual features to identify artistic styles is a more reliable approach for training the classifier.
Vision Language Models and Few Shot Prompting
Now we have shifted the focus to image classification, which presents a more complex challenge of classifying 500,000 images instead of prompts. For the Vision Language model, I chose the Llama 3.2 11B Vision Instruct model, which was released this past September. The model performs well on Visual Question Answering tasks, and is small enough to fit on our GPU, allowing us to process the large dataset without excessive inference costs.
In Snat’s technical blog, he utilizes a few-shot prompt template that was pretty effective in getting consistent classifications for the PDF urls. However, translating this approach to images with VLMs has some challenges. Images contain a lot more raw information than text tokens so it’s harder to generalize the relevant patterns from just a few images. As of today, I’m unsure if we are able to get consistent and accurate responses from few-shot prompting with VLMs, and I don’t think appending multiple example images would yield reliable results. Moreover, with the Llama Vision model, there is limited support when trying to process multiple images simultaneously and the Llama team specifically recommends single image inference for optimal performance.
To address these limitations, I used a two stage approach: First, I fed a single image into the Llama model with a specialized prompt to extract detailed analysis about the image characteristics.
You are an AI assistant specialized in detailed image analysis. Your task is to analyze the given image and provide a comprehensive description covering:
1. Core elements and subjects (context, setting)
2. Visual techniques and artistic approach
3. Composition and framing
4. Color palette and lighting dynamics
5. Technical aspects (quality, resolution, notable effects)
If needed, attached is original prompt that was provided with the image: {prompt}
Please provide your description in a clear, organized way that captures both the content and artistic elements of the image. Be specific about visual details while maintaining objective, descriptive language. Multiple styles can be identified if present.
If you cannot properly analyze the image, indicate this clearly.
The resulting detailed image description is then passed back into the Llama model for classification. Now that we have a text-based description for the image, we can use the few-shot prompt template effectively, and include about 8-10 examples for consistent style classification.
Finally, I didn’t want to limit the model to single style classification, as users often combine multiple artistic styles in generation playgrounds to blend different aesthetics in the images. For instance, in the JourneyDB paper, they tried classifying the style for Midjourney images and only achieved about 41% accuracy in single-style classification. To build a more robust classifier, we try to generate at least three style predictions per image.
Using vLLM for efficient large-scale inference
Classifying 500k images through our pipeline is computationally expensive, and third-party ML inference platforms charge around 300-400 dollars for this scale of processing, which I am reluctant to spend.
Fortunately, vLLM is a high-throughput inference engine that we can self-host for this process. vLLM significantly increases inferences speeds through techniques like continuous batching and PagedAttention, and we can get up to 24x higher throughput compared to the standard Huggingface transformers library. Moreover, they support LLMs and VLMs, including the Llama Vision model.
With an 8xA100 instance from Lambda Labs, our 11B model is small enough that we can load an instance of it across each of the GPUs. We shard each of the vLLM replicas across the 8 GPUs, and then we partition the 500k sample dataset to efficiently batch through the images, and then afterwards generate the classifications from the few-shot template.
On a side note: one thing I learned from implementing this process is that you actually need to import vLLM inside the child process function and not at the top level. This is because of how Python’s multiprocessing works with CUDA initialization. Each spawn mode gives each child process a new Python interpreter, and importing vLLM inside the function ensures that each process initializes CUDA with its own GPU assignment. If you try to set up CUDA before the spawning process, the GPU assignments won’t work correctly.
def child(rank, **sampling_params):
os.environ["CUDA_VISIBLE_DEVICES"] = str(rank)
from vllm import LLM
llm = LLM(
model="meta-llama/Llama-3.2-11B-Vision-Instruct",
tensor_parallel_size=1, # Use single GPU
enforce_eager=True,
...
)
sampling_params = SamplingParams(**sampling_params)
...
The final workflow is as follows:
- Take a 500k sample of images from DiffusionDB.
- Generate image descriptions for each of the images with the Llama model.
- Run the image descriptions through the few-shot template for final classification.
Overall, setting up the pipeline and processing the 500k samples took about 2 days to complete.
Dataset Balancing
In our initial pass of the 500k samples, we get about 600 categories.
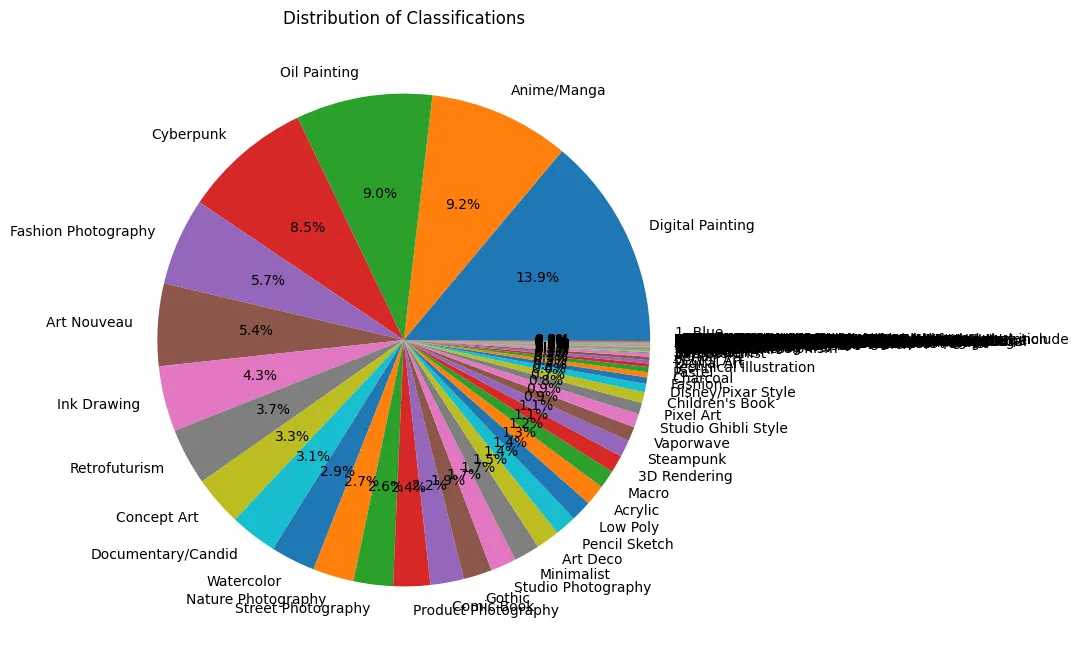
To make this more manageable, we combine similar categories together, and we dropped any categories that had less than 5000 classifications - this brings us down to about 18 different categories.
Unfortunately, the distribution of classes is skewed, and some categories dominate the distributions in our dataset. To fix this, we cap any categories with over 30k samples and randomly select examples from each of these categories. For categories under this threshold, we use the albumentations library to augment data, and upsample them up to 30k samples. Through albumentations we can create variations in the data through rotations, cropping, brightness, contrast adjustments, blurs, and noise variations. These augmentations will help us prevent any overfitting and maintain the image recognizability in our classes.
The resulting balanced dataset is about 540k samples, and we can now finetune a classifier that can recognize the image styles more effectively in our larger dataset.
Finetuning CLIP
Now for the simplest part - finetuning CLIP! Since we are focused on image style detection, we only need to add a linear classifier head on top of CLIP’s frozen visual encoder. CLIP’s visual understanding is very strong, and it has been pre-trained on massive image-text datasets. Moreover, it is a key component in many text-to-image pipelines. We are specifically finetuning ViT-L/14 CLIP image encoder (same model used in Stable Diffusion) and we will convert the images into 768-dimensional vectors.
class CLIPFineTuner(nn.Module):
def __init__(self, model, num_classes):
super(CLIPFineTuner, self).__init__()
self.model = model
# Freeze all CLIP parameters
for param in self.model.parameters():
param.requires_grad = False
# Only the classifier will be trainable
self.classifier = nn.Linear(model.visual.output_dim, num_classes)
def forward(self, image):
# Keep no_grad since we're not training CLIP
with torch.no_grad():
image_features = self.model.encode_image(image).float()
image_features /= image_features.norm(dim=-1, keepdim=True)
return self.classifier(image_features)
For training, we split our 540k sampled images into 85% training and 15% validation sets. We will evaluate this as a multi-label classification problem, in that we will look at top-3 predictions against each of the image’s actual style categories.
To prepare our data, we need to ensure that the images match CLIP's expected input format. The first tuple under transforms.Normalize() is the mean values for each of the RGB channels of CLIP, and the second tuple is standard deviation values for each of the RGB channels. This ensures that our input images will match the distribution CLIP was trained on, which will lead to more stable and accurate training.
class DiffusionDataset(Dataset):
def __init__(self, data):
self.data = data
self.transform = transforms.Compose([
transforms.Resize((224, 224)),
transforms.ToTensor(),
transforms.Normalize(
(0.48145466, 0.4578275, 0.40821073), # CLIP's RGB means
(0.26862954, 0.26130258, 0.27577711) # CLIP's RGB standard deviations
)
])
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data.iloc[idx]
image_data = base64.b64decode(item['image'])
image = Image.open(io.BytesIO(image_data))
category = item['classification']
label = categories.index(category)
return self.transform(image), label
After finetuning CLIP we achieve a 73.02% accuracy in predicting the top 3 categories. This is a pretty solid result! If we did further cleaning of the noisy data, and collected additional data with images from other AI art platforms like Midjourney or FLUX.1, we could increase both the performance and robustness of this classifier.
Visualizing Style Distributions
Finally, the last step was to visualize some of the image playgrounds that had public datasets. I only plotted the top style of each of the images, but it's worth noting that images often incorporate multiple styles.
Stable Diffusion
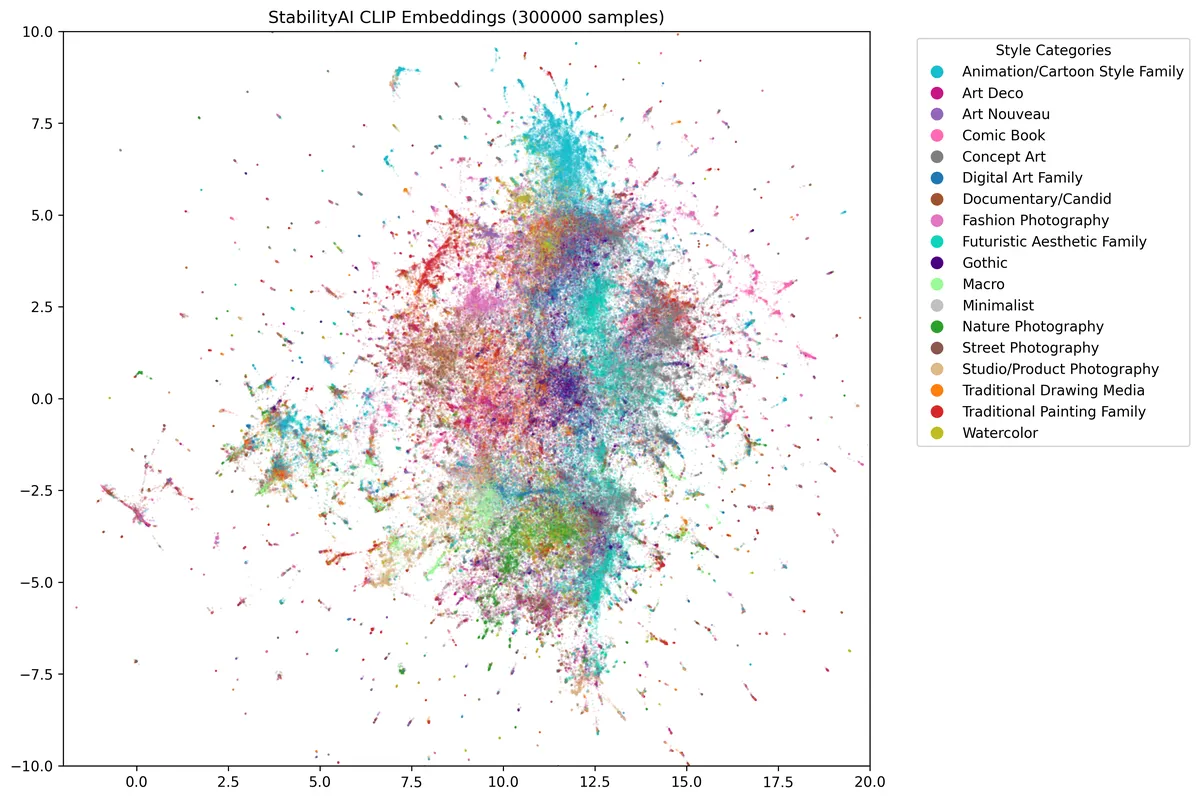
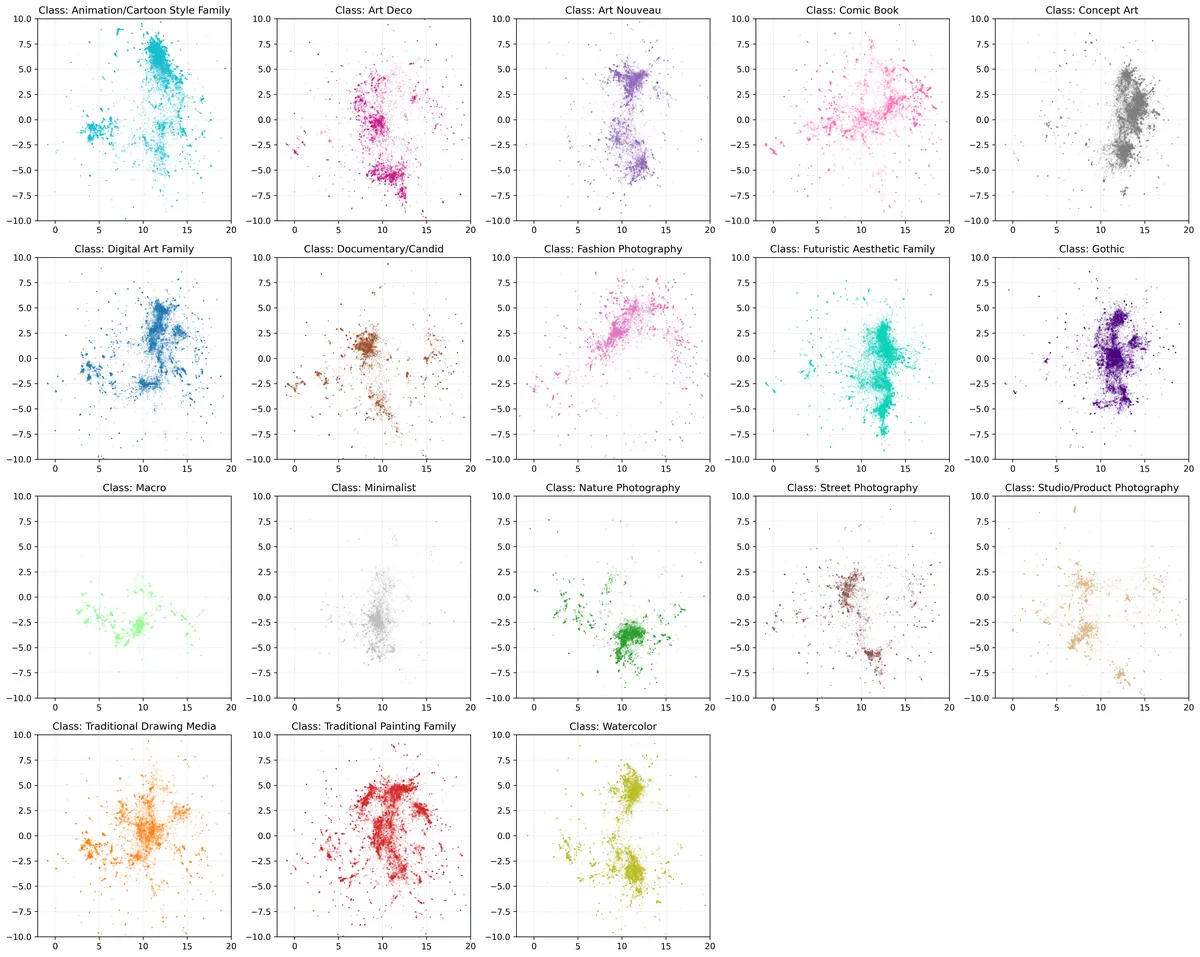
From DiffusionDB, I analyzed a random sample of 300,000 images, separate from our labeled training dataset. The UMAP visualizations reveal some cool patterns in how styles cluster.
Photography-based styles have more tighter, concentrated clusters, which suggest that there are consistent visual characteristics across these images. In contrast, traditional painting and water color styles display more dispersed distributions indicating greater variety in the visual representations.
The visualization also reveals significant style overlap in the central region where multiple styles intersect, which could indicate that users are blending different artistic influences when generating images with Stable Diffusion.
PlaygroundAI
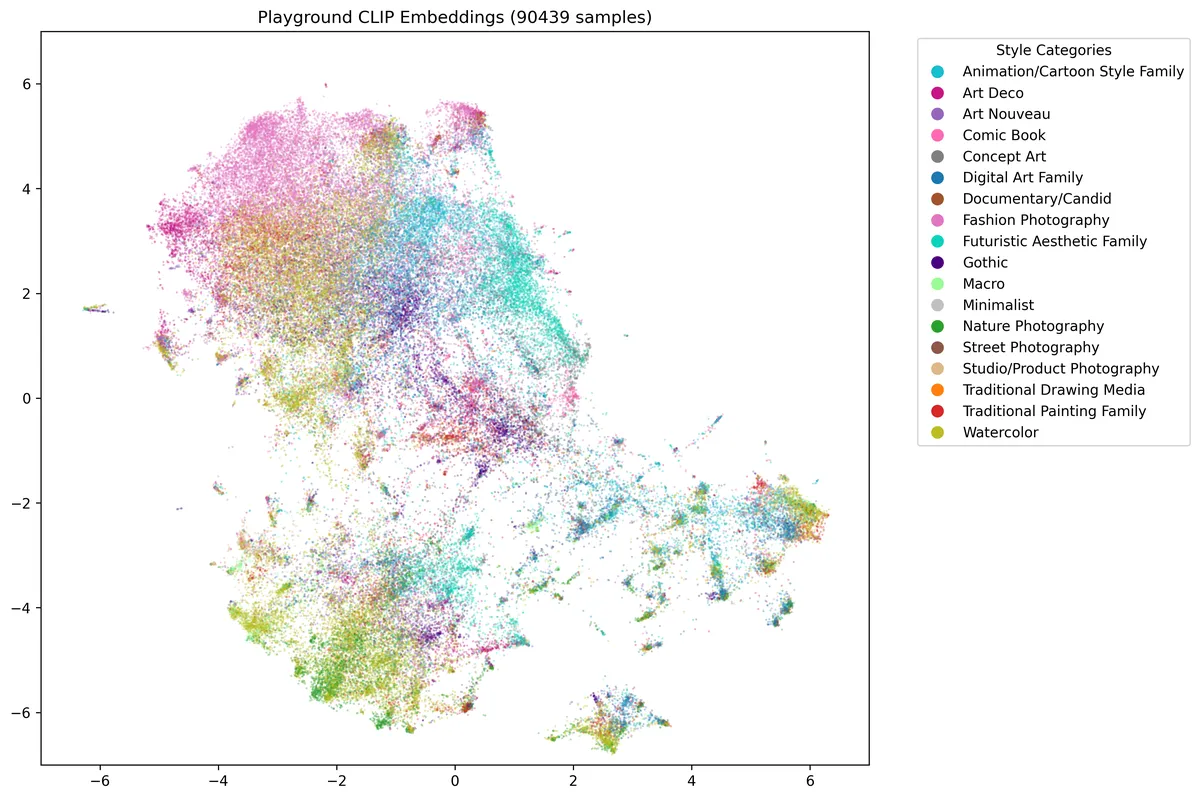
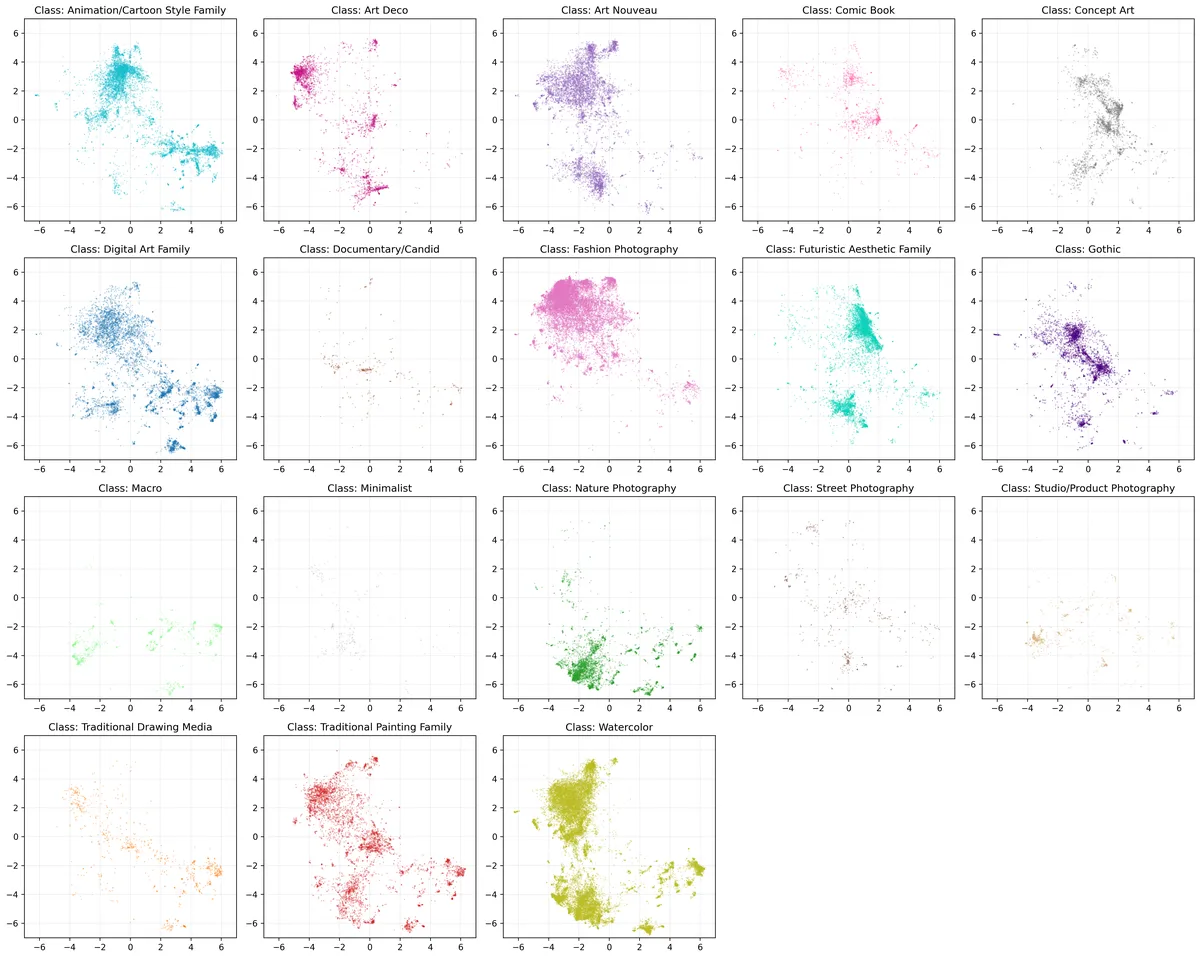
For PlaygroundAI I used this dataset from Huggingface and scraped about 90k images through URL requests before my Lambda Labs instance terminated. While a larger sample would have provided a more comprehensive view, you can see in the UMAP visualization there are some distinct style patterns in the platform.
Some cool things I noticed were that fashion photography images had more dense clustering, which could suggest that PlaygroundAI does pretty well at capturing consistent fashion characteristics. Also comparing it to Stable Diffusion’s visualization, the Art Nouveau and Gothic styles also have similar distinct clusters but are less isolated, which could indicate that users are blending these styles more in the PlaygroundAI platform.
Midjourney
Finally, I classified about 2 million images from the JourneyDB dataset, which contains images scraped from the Midjourney discord. Midjourney shows rich style blending, particularly evident in the central region of the visualization where there's significant mixing and smooth transitions between different artistic categories. Even with clustered categories like photography, they are more diffuse in this visualization, which suggests users are blending styles more in Midjourney, likely due to their ability to control style fusion through specific prompt syntax and parameters.
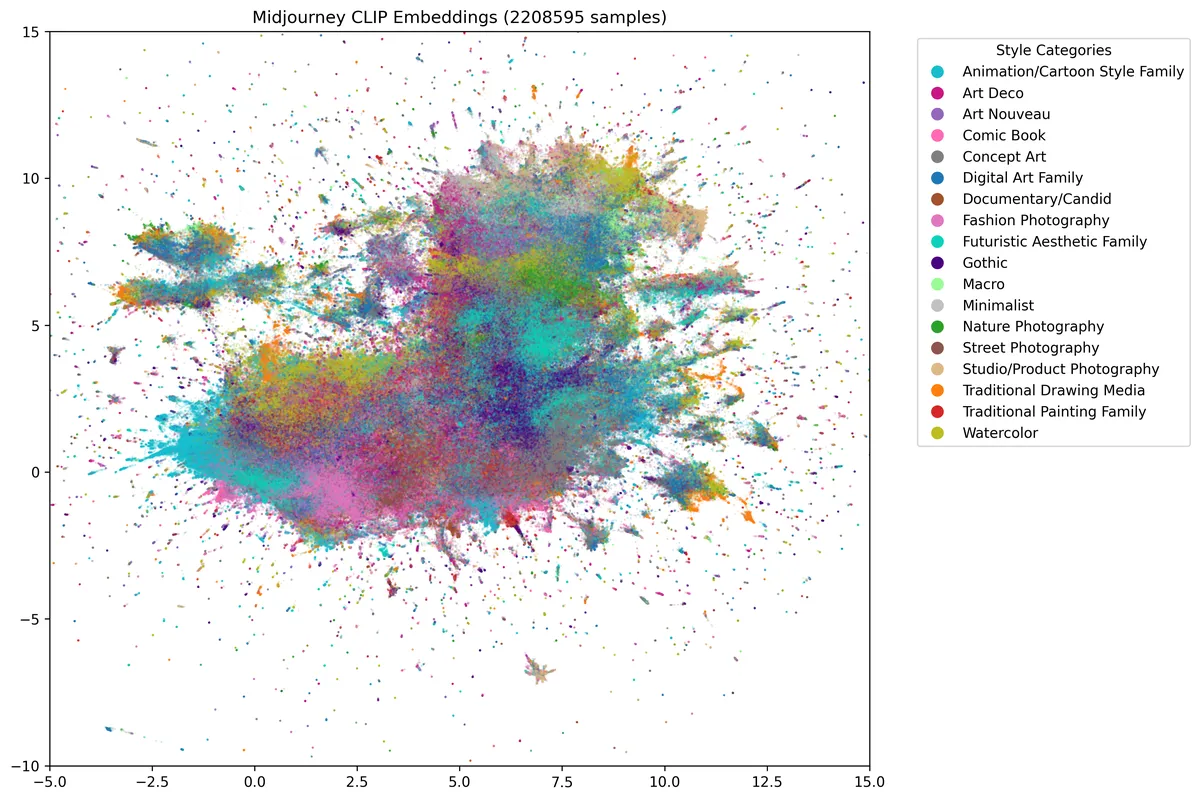
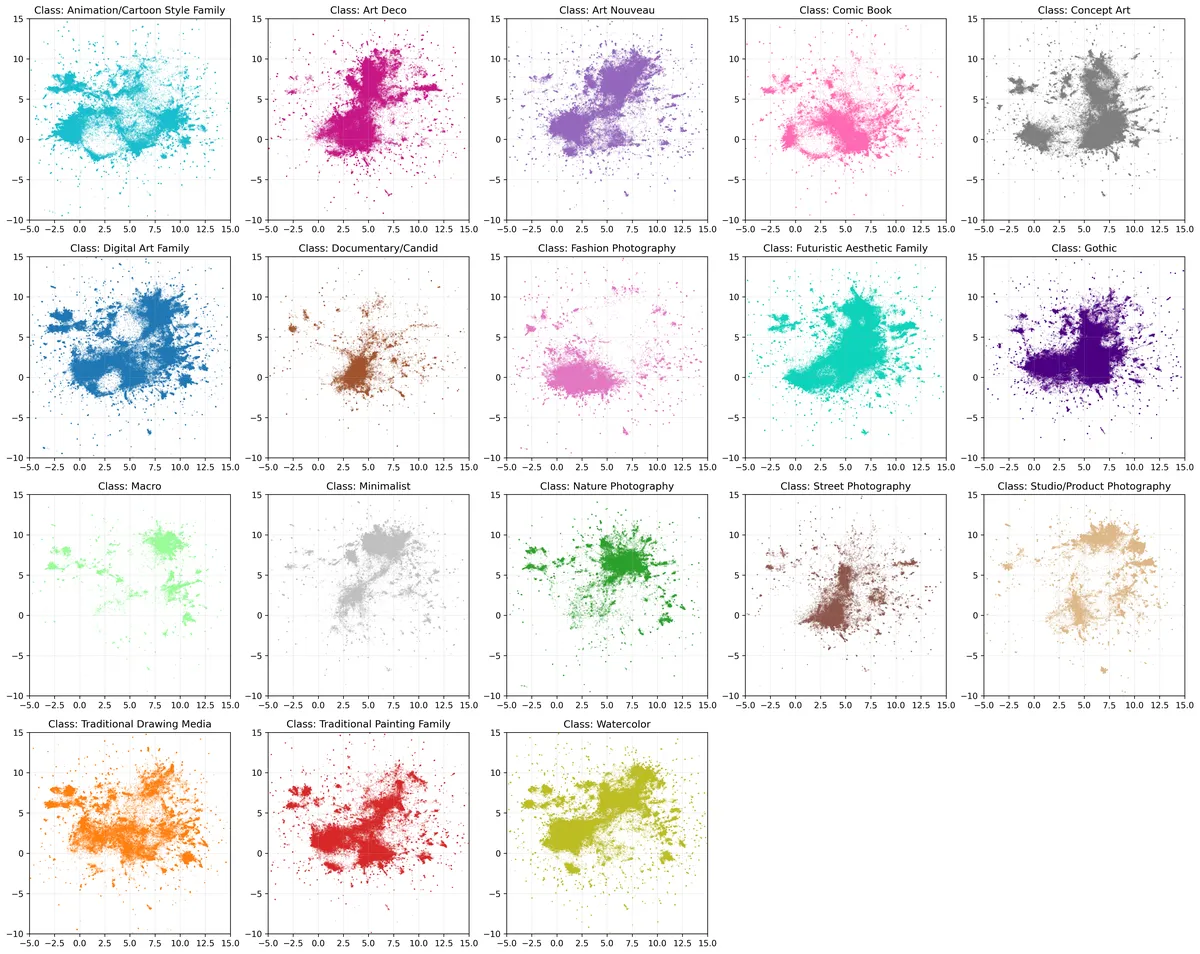
Conclusion
In the future, I would love to improve the accuracy of my classifier and incorporate other image datasets besides DiffusionDB. Moreover, I think it could be cool to analyze how these AI art platforms change, and analyze more recent snapshots of data to see how these platforms and styles evolve overtime. Lastly, it would be interesting to examine style distributions in newer models like LumaLab’s Photon and BlackForestLab’s FLUX.1.
Special thanks to Van for the vLLM suggestion, @snats_xyz for the initial inspiration of this the article, and to the authors of DiffusionDB for their well-curated dataset. This analysis wouldn't have been possible without the datasets indirectly provided by PlaygroundAI, Midjourney, and StabilityAI.