Multilingual token compression in GPT-o family models
Disclaimer: I wrote this article before OpenAI released o1, which now hides its "reasoning" tokens making them inaccessible through the tiktoken library. I think o1 uses the same base tokenizer as GPT-o, but unfortunately we can no longer observe this directly.
GPT-o introduces a new tokenizer o200k_base, which both doubles the model's vocabulary size to 200k (previously 100k with GPT-4) and significantly improves token compression, especially for non-English tokens.

Source: GPT-o release
Compression
For non-Latin scripts, o200k_base achieves significantly higher token compression compared to GPT-4's c100k_base, demonstrating more efficient word tokenization.
For example, looking at the Tamil sentence நீ எப்படி இருக்கிறாய்? நான் நல்லா இருக்கேன். (translation: How are you? I am fine.), c100k_base creates many more token boundaries. These token boundaries occur not only between words, but also between letters and their associated diacritics (marks that are added to letters that tell you how to pronounce them -> e.g. French accents â, ê, î, ô, û).
A simple letter/diacritic combination like நீ (translation: you in Tamil) is split into 4 separate tokens!
நீ -> [20627, 101, 32601, 222]
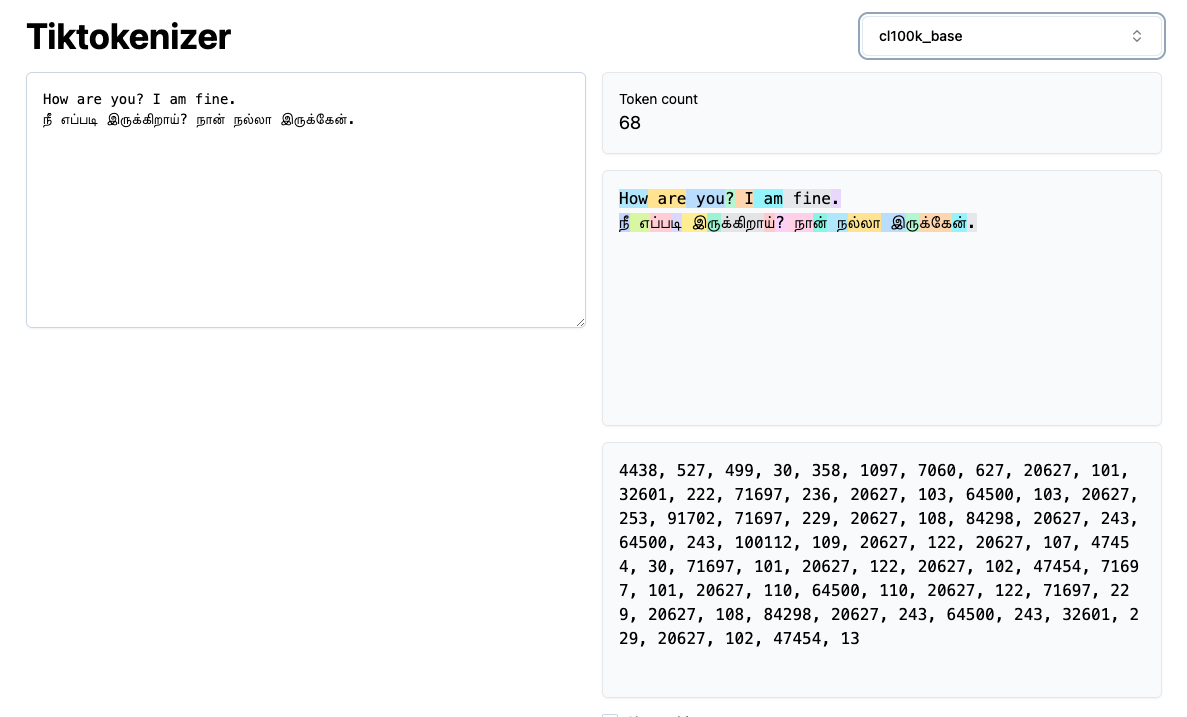
c100k_base visualized in tiktokenizer
In contrast, o200k_base groups words together far more efficiently within their respective word boundaries. This improved grouping captures not only the whole word but also any associated diacritics.
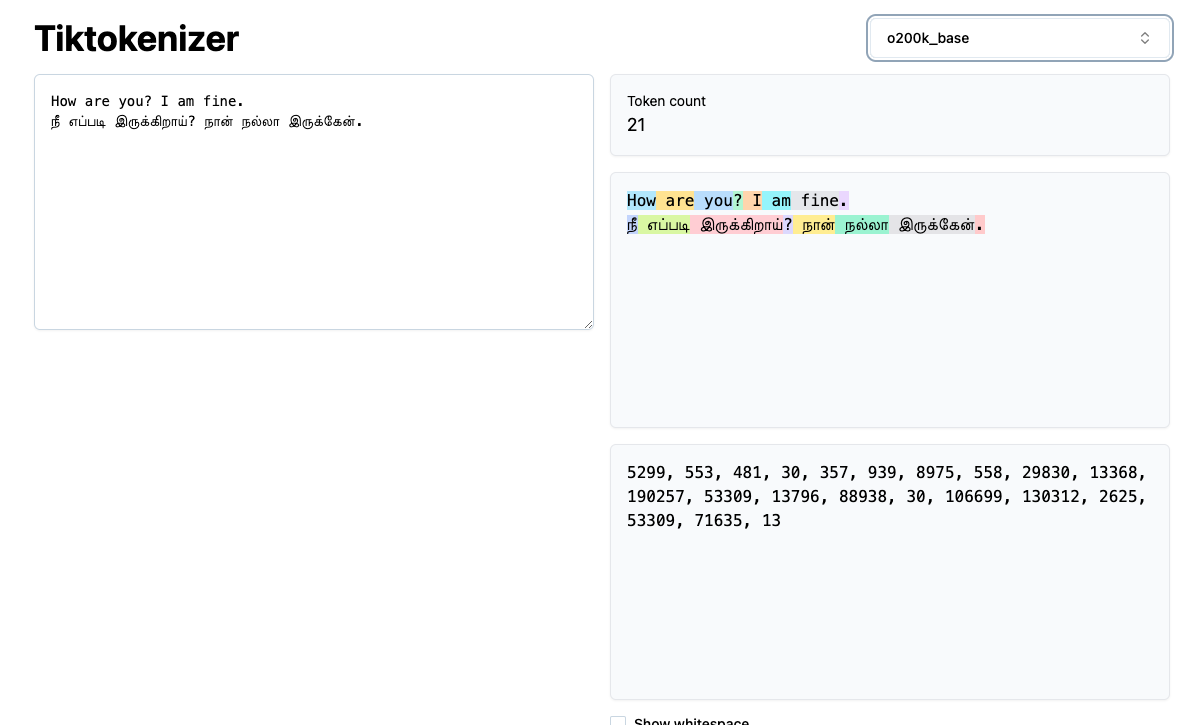
68 tokens to 21 tokens → 3.2x compression!
I'm not sure how much of a difference there is between GPT-o’s and GPT-4’s training data for both the model and the tokenizer, or how much additional non-English data went into training the GPT-o tokenizer. However, examining the two tokenizers in the tiktoken github repo, reveals a major upgrade in the regex handling word boundary splits for o200k_base compared to c100k_base. This upgrade results in much more efficient groupings for GPT-o.
Brief Primer on Byte Pair Encoding
Byte Pair Encoding (BPE), a sub-word language modeling algorithm, trains tokenizers on large datasets. The process begins by encoding text data into individual UTF-8 bytes (a byte-level version of BPE, starting with 256 unicode points). BPE then iteratively merges the most frequent pair of consecutive bytes in the dataset, which forms a new symbol that is added into the tokenizer vocabulary.
This process continues until we have 200,000 merges (where 200k vocab size comes from). These merges represent our vocabulary set, which we can use to decode and encode sentences that go into our model.
This greedy approach, however, can produce many duplicate words in our token vocabulary, differing only in slight punctuation (Ex: dog, dog., dog!, all appearing in our vocab).
Regex solves this issue by preventing the BPE algorithm from merging across regex boundaries. This approach produces more unique words in our vocabulary instead of small variations of the same word.
Regex Patterns
def cl100k_base():
# ... (previous code omitted)
"pat_str": r"""'(?i:[sdmt]|ll|ve|re)|[^\r\n\p{L}\p{N}]?+\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]++[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+""",
# ... (remaining code omitted)
GPT-4's regex pattern creates the following token boundaries for our training dataset:
- contractions
- words with or without leading punctuation
- numbers ranging 1-3 digits
- punctuation and symbols
- newlines
- two different patterns for white space
Notably, \p{L} occurs frequently in the pattern. \p{L} matches any Unicode letter from any language, capturing both Latin and non-Latin characters. For purely Latin characters, this approach suffices, as frequently used multilingual characters typically have determined codepoints.
However, when handling non-Latin characters and marks, a major issue occurs.
gpt4pat = re.compile(r"""'(?i:[sdmt]|ll|ve|re)|[^\r\n\p{L}\p{N}]?+\p{L}+|\p{N}{1,3}| ?[^\s\p{L}\p{N}]++[\r\n]*|\s*[\r\n]|\s+(?!\S)|\s+""")
text = "How are you? I am fine. நீ எப்படி இருக்கிறாய்? நான் நல்லா இருக்கேன்."
>>> ['How', ' are', ' you', '?', ' I', ' am', ' fine', '.', ' ந', 'ீ', ' எப', '்பட', 'ி', ' இர', 'ுக', '்க', 'ிற', 'ாய', '்?', ' ந', 'ான', '்', ' நல', '்ல', 'ா', ' இர', 'ுக', '்க', 'ேன', '்.']
When handling non-Latin scripts, \p{L} doesn't include diacritical marks or modifiers. Instead, c100k_base forces splits on the above sentence at every Tamil base letter with an associate diacritic mark, which causes a massive increase in the tokenizer count for this sentence.
def o200k_base():
# ... (previous code omitted)
pat_str = "|".join(
[
r"""[^\r\n\p{L}\p{N}]?[\p{Lu}\p{Lt}\p{Lm}\p{Lo}\p{M}]*[\p{Ll}\p{Lm}\p{Lo}\p{M}]+(?i:'s|'t|'re|'ve|'m|'ll|'d)?""",
r"""[^\r\n\p{L}\p{N}]?[\p{Lu}\p{Lt}\p{Lm}\p{Lo}\p{M}]+[\p{Ll}\p{Lm}\p{Lo}\p{M}]*(?i:'s|'t|'re|'ve|'m|'ll|'d)?""",
r"""\p{N}{1,3}""",
r""" ?[^\s\p{L}\p{N}]+[\r\n/]*""",
r"""\s*[\r\n]+""",
r"""\s+(?!\S)""",
r"""\s+""",
]
)
# ... (remaining code omitted)
o200k_base fixes this issue by introducing several new Unicode character categories. Instead of having one \p{L} for all Unicode letters, we now break it down based on the specific type of Unicode letter we are dealing with:
\p{Lu}: Uppercase letters\p{Lt}: Titlecase letters\p{Lm}: Modifier letters\p{Lo}: Other letters (includes letters from non-Latin scripts)\p{M}: Marks (includes diacritical marks and other modifiers)\p{Ll}: Lowercase letters
[\p{Lu}\p{Lt}\p{Lm}\p{Lo}\p{M}]+[\p{Ll}\p{Lm}\p{Lo}\p{M}]
The pattern above allows for any combination of uppercase, titlecase, modifier, other letters, and marks, followed by lowercase, modifier, other letters and marks. Thus, we effectively capture words with diacritics and modifier letters anywhere in the word - beginning, middle, or end.
By including \p{Lo}, \p{Lm}, and \p{M}, o200k_base significantly improve its performance across a wide range of languages and scripts.
text = "How are you? I am fine. நீ எப்படி இருக்கிறாய்? நான் நல்லா இருக்கேன்."
gpt4opat = re.compile("|".join(
[
r"""[^\r\n\p{L}\p{N}]?[\p{Lu}\p{Lt}\p{Lm}\p{Lo}\p{M}]*[\p{Ll}\p{Lm}\p{Lo}\p{M}]+(?i:'s|'t|'re|'ve|'m|'ll|'d)?""",
r"""[^\r\n\p{L}\p{N}]?[\p{Lu}\p{Lt}\p{Lm}\p{Lo}\p{M}]+[\p{Ll}\p{Lm}\p{Lo}\p{M}]*(?i:'s|'t|'re|'ve|'m|'ll|'d)?""",
r"""\p{N}{1,3}""",
r""" ?[^\s\p{L}\p{N}]+[\r\n/]*""",
r"""\s*[\r\n]+""",
r"""\s+(?!\S)""",
r"""\s+""",
]))
>>> ['How', ' are', ' you', '?', ' I', ' am', ' fine', '.', ' நீ', ' எப்படி', ' இருக்கிறாய்', '?', ' நான்', ' நல்லா', ' இருக்கேன்', '.']
As a result, this regex change enables GPT-o to group multilingual words more efficiently, which boosts compression during tokenizer training. However, the new regex logic is extremely sensitive to complex patterns, and with clever manipulation can still lead to unstable splits, where just adding one or two characters can drastically change the tokenization output.
This is a known issue at OpenAI at this point, and their regex approach has grown and evolved since GPT-2's implementation, which was trained mostly on English data. Hopefully, research labs in the future can explore different methods for tokenization sans regex.
This article was inspired by Shantanu's reply to a GitHub issue about GPT-o's regex changes and it's effects on Unicode mark points.